孵化 DeepSeek 的量化交易:一个数据驱动的隐秘世界
1994年,量化公司是当时最神秘最热门的技术公司,他们雇用数学家和物理学家,成批买来高性能计算机做交易。这个行业里的标杆公司是D.E.Shaw,它能在一天内贡献纽交所超2%的订单量。
这一年,D.E.Shaw为计算机行业做了两个贡献。一个副总裁带队,做出了当时罕见的免费电子邮件产品Juno,成功上市;另一个副总裁离职,带着自己和老板讨论产生的好点子开车去了西雅图,做出了全世界的电商鼻祖、市值超过20000亿美元的亚马逊。
30 年后,又有一家量化公司的 “副业” 影响整个计算机行业:管理数百亿元的中国头部量化公司幻方,推出大语言模型 DeepSeek R1,没花一分钱营销就震撼全球,用户涌来的速度甚至快过早年的抖音。
贝索斯创办亚马逊,或者梁文锋造出DeepSeek的主要原因自然不是因为他们做过量化,而是因为他们骨子里都是创业者。但量化投资这个极度追求人才密度且极度保密的行业文化,确实提供了适合大模型研发的环境。
招来一群聪明人不必然导致创新,叠加一个简单的环境才够。量化公司证明了这一点,DeepSeek则证明这也适用于大模型研发。
剥离主观因素,在数据里挖掘规律
“很多主观投资说难听点,就是靠打听。”一名从业几十年、调研过数千只基金的投资人说。基金经理们也钻研公开的财务资料,但他们同样乐于组织业内人士研讨会、支付每小时上千元的专家咨询费,甚至雇上千人守在咖啡店门口拍视频,只为更早获得独家信息,抢先同行一步下注。
于是,人脉变得和经验一样重要。尽管桥水基金创始人瑞·达利欧把利率、汇率的变动原理写成书,反复讲桥水基金凭它们投资,但《纽约时报》的记者觉得达利欧赚钱的真正秘诀是讨好宏观政策决定者,靠他们“透题”赚钱,也写了本书论证。
量化公司完全放弃这些捷径。他们相信任何事都有人更早知道,自己也没能力超越对手做任何判断。他们全部投资决策基于一个简单的事实:人类行为总是不断重复,因此价格运动有规律可循,而计算机可以捕捉到这个规律。
足够多人靠逻辑交易,会产生规律。
可口可乐和百事可乐都做汽水生意,受同样的市场环境影响。如果两家公司股价差距没来由地扩大或收窄,那至少有一家定价错误、价差总要回归。四十年前,先发现这个机会的投资者靠程序监测六、七只相关股票的价差变动,就能撑起一只管理3000万美元的基金。
足够多的人靠情绪交易,也产生规律。
可口可乐的投资者中总有自信过头的,他们会更倾向于跟着自己喜欢的消息买入,而把自己不喜欢的消息当作噪音。由此,新消息只会将可口可乐股价向上顶,学界发现过去收益好的公司,未来大概率还会好下去,把这规律称为“动量效应”。
量化研究员贾乾说,股票每天收益的波动中,最多可能有5%可被解释。他的工作就是找到能刻画规律、解释波动的“因子”,基于它们构建投资策略。可口可乐未来走势与百事可乐过往股价、可口可乐过往涨幅相关,股价、涨幅数据就能作为“因子”投入量化模型。
因子可能是上面这样容易理解的信息,也可以更加复杂。
特朗普习惯把各种耸人听闻的想法随手发在Twitter上,他第一任期内,J.P.Morgan的研究员通过程序分析特朗普上万条推文的语义、构建“Volfefe”指数,并验证它可以解释美国国债利率变动。靠买卖国债赚钱的量化模型可以把Volfefe指数当作因子。
量化公司文艺复兴创始人西蒙斯研究过月球周期对市场的影响。路径之一可能是:月动影响潮汐、潮汐影响航运、航运影响油价。但他最终无功而返。传导链条太长、中间变量太多,因子对价格影响就难以识别。
机器学习方法在量化行业普及后,很多左右股价变化的因子已经完全无法用逻辑理解。研究员确定评价因子的标准,输入开盘价、收盘价、成交量等“原始因子”,程序就能自动组合、迭代出更能预测股价的新因子。投资机构WorldQuant曾分享过一个实际用于交易的“较为简单”的因子:
((rank(correlation(sum(((open*0.178404)+(close*(1-0.178404))),12.7054),sum(adv120,12.7054),16.6208))<rank(delta(((((high+low/2)*0.178404)+(vwap*(1-0.178404))),3.69741)))*-1)
除了能增加因子对价格的解释能力外,没人知道公式中的0.178404等数字有什么现实意义。但量化研究员不介意。“如果是意义非常明显的信号,早就被用于交易了。有些信号你不理解,但它们就在那里,而且可能相对较强。”文艺复兴CEO彼得·布朗说。
量化研究员轩浩告诉我们,基于现实意义、拍脑袋想因子十分困难,“一天能想十个,就是天才了”。人找的因子通常能持续几个月、半年帮基金赚到钱。而机器挖出来的因子失效非常快,“但架不住每天能产生几千个。”
如果知道因子的人多了,抢着做同一种交易,它就会失效。这让量化行业在保密方面近乎偏执。头部量化公司会要求离职员工 18-24 个月内既不能自己交易、也不能去其他公司任职。“俗称 Gardening Leave,回家种花。” 轩浩说。
LinkedIn 简历中的 Gardening Leave
D.E. Shaw 创始人大卫 · 肖曾说自己公司安保水平媲美中央情报局。被记者问 D.E Shaw 是否用神经网络算法构思策略时,这名拥有数十亿美元财富的创始人回答:“我可以告诉你,然后必须杀了你。”
单次买卖可赚可赔,量化公司只关注大量交易时击败市场的概率。2000年初,文艺复兴的大奖章基金每天交易15-30万次,“我们只在50.75%的情况下是对的。”一名员工说,但这已足够成就公司大奖章基金一年管38亿美元、赚21亿美元的成绩。
雇聪明人,在简单环境里解决复杂问题
美国国家数学博物馆每年举行一次“数学大师”锦标赛:聚起一群聪明人,比谁能在限时内能解出最多这样的数学问题:找到最小正整数m,使m²+7m+89能被77整除。
2014 年比赛夜的参与者有陶哲轩,他 24 岁成为加州大学洛杉矶分校数学系终身教授,31 岁获得 “菲尔兹奖”——数学界的诺贝尔奖。不过他只是第二,赢过他的是约翰 · 奥弗德克,量化公司 Two Sigma 的联合创始人。
奥弗德克可能也不是 Two Sigma 最聪明的人。2015 年时,这家公司已经招了 130 名博士和 6 名国际数学奥林匹克竞赛获奖者。奥弗德克前东家 D.E. Shaw 直接说自己招聘时有 “毫无歉意的精英主义”,前美国财政部长、哈佛大学校长劳伦斯 · 萨默斯在 2006 年想去 D.E. Shaw 工作,同样要做智力测验。
受量化公司青睐的候选人往往来自数学、计算机、统计学等专业,金融、商科背景不是加分项。
创立幻方前,梁文锋在浙江大学读通信工程,之后也偏好雇高中或大学时参加全国或国际学科竞赛,比如NOI(全国青少年信息学奥林匹克竞赛)、IOI(国际信息学奥林匹克竞赛),拿到好名次、最好是金牌的年轻人。没竞赛背景,最好本科能考上北大、浙大、清华等高校,学计算机、电子信息工程专业。
“科学家做这行的优势不是数学或计算能力,而在于他们的科学思维。”西蒙斯说,他们更不可能接受统计学上的偶然事件。
2022年2月,一名拿过奖的首席分析师写“定量分析”研报说宁德时代未来可能跌超20%。尽管他事后被证明结论正确,但推导方式却诉诸偶然:一年前,同为行业龙头的贵州茅台面临相似的市场环境,两家公司股价走势长得也像,他据此推测茅台过去的跌幅可以指引宁德时代的未来表现。
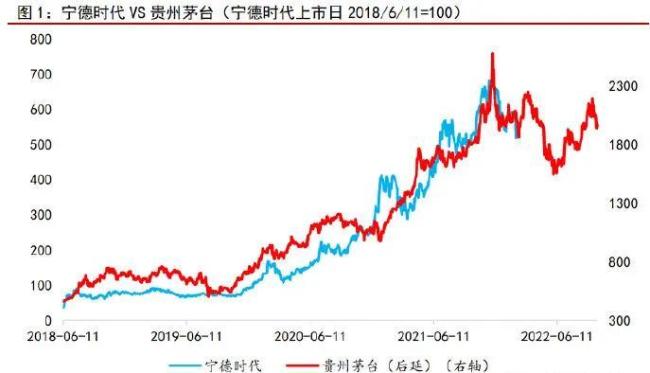
现在已经被撤回的研报中,贵州茅台和宁德时代的走势对比
量化则是不同的研究范式。Two Sigma 面试员工时,一个例题是如何用数学方法验证 “CEO 离职,公司股价下跌”。应试者和面试官会讨论实验方案:
如何确定收集的数据样本足够多、足够全面?如何定义下跌——是用一天的跌幅,还是一周、一个月?如何控制对照组和测试组尽可能相似?如何区分CEO离职是因为能力不足还是正常退休?如何区分股价下跌是因为CEO离职,还是在被大盘向下拽?用哪个统计值做推断、它超过多少时,要以多少置信度推翻假设?
哪怕选邻居时,量化公司也和传统金融行业保持距离。Two Sigma、D.E. Shaw 们不在华尔街设办公室;幻方总部位于杭州,它和同行们的北京办公室也聚集在清华科技园,而不是国贸、金融街。选址本身就是一个宣言:不靠人情世故、不靠勾兑信息,潜心研究也能赚大钱。
去过D.E.Shaw办公室的投资人觉得那里安静得像图书馆研究室;文艺复兴公司内有能容纳100人的礼堂,定期举办科学讲座,比如结直肠癌研究的最新进展。“当听到有人谈论有趣的统计应用时,有助于激发思考。”一名员工说。
希望聪明人持续创新,最好的方法是减少管控、干预。
轩浩就职于一家全球顶级量化投资机构,其内部有多个小组互不透风、独立交易,就像一个个小投资机构:各组只要控制好风险,投资方法论并不需要一致,每年扣掉交给公司的提成、数据接口等成本后,剩下的利润都归自己所有。“有一个组瞄准一种另类资产,做一套策略赚了数十亿元。所有人都财富自由了。”
另一类量化公司偏好集体决策,全员共同打磨一个交易系统,但依然给员工自由发挥的空间。在文艺复兴,员工可以出入同事办公室,寻求建议或发起合作。研究员花大量时间用于成果展示,“如果没有取得太大的进步,你会感到有压力。”一名员工说。评判标准十分清晰:一天结束,账户里的钱是变多还是变少。
这与互联网公司显著不同。大厂的中层管理者把手下人数与晋升机会挂钩,不会轻易允许下属参与其他团队分工,自己还要在双月会上争抢更多业务领地。所有人都要在KPI或OKR中提前写定自己下周、下个月、下个季度要干什么。在难以分清个人成绩和公司体系力量的大公司,只能用各种管理手段。
幻方的管理风格与文艺复兴类似,并被DeepSeek团队继承。后者办公区会议室两侧都设置了随手能推开的门,“给偶然留出空隙”。“我们一般不前置分工。”梁文锋说,员工没有KPI,“遇到问题,自己就会拉人讨论。”当想法显出潜力,公司会自上而下调配资源。
一种方式,用到极致
把数十亿美元交给机器打点,完全相信它们是件反人性的事,哪怕对行业先驱也如此。最早尝试机器学习算法时,西蒙斯并不放心:“我不理解为什么模型一直要求买入而不是卖出?这就是个黑箱!”
缓解焦虑不是靠退回人工干预,而是穷尽数据、算力,将算法的潜力发挥到极致。文艺复兴的数据库从 18 世纪开始,现在 “每天增长 40TB(1TB = 1000GB)”,他们还有 “52000 个计算核心与 150GB 每秒的全球传输速度”。Two Sigma 则有 “超过 7200 个服务器”“来自 10000 多个数据源的超过 300PB 数据(1PB = 1000TB)”。
调用资源、设计量化策略时则要执着于每一个细节。轩浩举例:一个模型预测股价要涨20%,应该以什么概率相信它?模型说要下1000单,那应该在10秒、20秒还是1分钟内执行完?卖的时候,是真要等到涨到20%、市场交易量变小的时候,还是趁有人愿意买,涨15%就提前止盈?
不是每一分投入都有相应的回报,结果出现前,量化研究员甚至不确定自己努力方向是否正确。伊黎试过从文本信息中提取因子,先人工看完1000条样本、打上标签,用它们训练一个自动打标的语义分析模型,还要训练另一个模型验证打标准确性。输入第三个模型分析后,她终于得出几十个因子,测试完,所幸有五个可以用。
大模型迭代与之类似。GPT模型理论架构最早来自Google,OpenAI成为最终受益者,是因为敢在前景模糊时,租卡、买数据,花千万美元一次又一次训练更大的模型。1.17亿参数,表现平平;15亿,仍不惊艳;1750亿,智能涌现。
黄仁勋问OpenAI联合创始人苏茨克沃:研发GPT模型时,你一直相信扩大规模能提高性能吗?“这是一个直觉。我有一个很强烈的信念,更大意味着更好。”苏茨克沃回答。
一个量化从业者感慨梁文锋从浙大信息与通信工程专业毕业后,没有选择当时很好、之后会更好的就业机会,自己花几年闭门琢磨用算法买股票,“这么搞就不好再找工作了”。
到了2021年,大语言模型的影响主要还停留在学界,ChatGPT没诞生。当时头部量化投资公司个个用了机器学习,但只有幻方花出上亿元买来一万张英伟达显卡,运行各种大型AI模型。
成功的创业者往往押中一套正确的方法,将它贯彻到极致。前者多少靠运气,后者只能靠信念,是AI取代不了的决策。
相关推荐:
 2025-03-12
2025-03-12 2025-03-12
2025-03-12 2025-03-12
2025-03-12


