海外研究者揭穿围绕DeepSeek的谣言 澄清五大误解
2025-02-05 来源:pengjian
围绕 DeepSeek 的谣言实在太多了。面对 DeepSeek R1 这个似乎「一夜之间」出现的先进大模型,全世界已经陷入了没日没夜的大讨论。从它的模型能力是否真的先进,到是不是真的只用了 550W 进行训练,再到神秘的研究团队,每个角度都是话题。
虽然 R1 是开源的,各种夸张猜测还是层出不穷,有人说训练 R1 实际上使用的算力远超论文所说的,有人质疑 R1 的技术创新,甚至还有人说 DeepSeek 实际的目标是做空。近日,知名生成式 AI 创业公司 Stability AI 的前研究主管 Tanishq Abraham 撰文揭穿了围绕 DeepSeek 的一系列谬论。

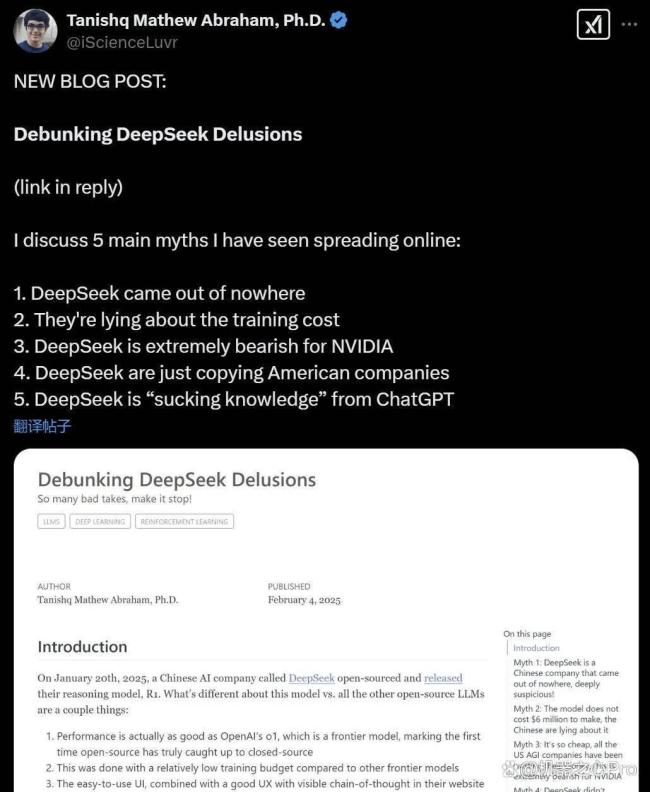
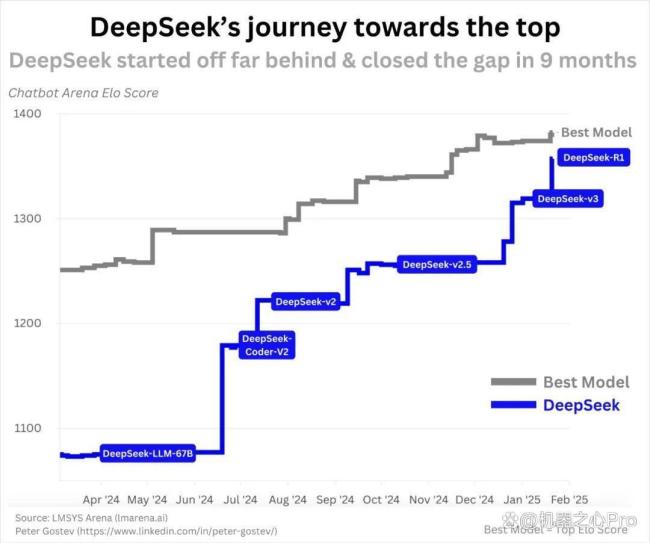
今年 1 月 20 日,DeepSeek 开源的强推理模型 R1 震撼了世人,与其他所有开源大语言模型(LLM)相比,该模型的不同之处在于以下几点:性能实际上与 OpenAI 的 o1 一样好,这是一个先进的模型,标志着开源首次真正赶上闭源;与其他先进模型相比,R1 是在相对较低的训练预算下完成的;易于使用的用户界面,加上其网站和应用程序中具有可见思路链的良好用户体验,吸引了数百万新用户。
鉴于 DeepSeek 是一家中国公司,美国及其一众科技公司纷纷指责新模型存在各种「国家安全问题」。因此,有关该模型的错误信息泛滥成灾。这篇博文旨在反驳自 DeepSeek 发布以来许多与人工智能相关的极其糟糕的评论,并以一名工作在生成式人工智能前沿的 AI 研究人员的身份提供客观的看法。
相关推荐:
 2025-02-23
2025-02-23 2025-02-23
2025-02-23 2025-02-23
2025-02-23
